Understanding API Pagination
Any JSON API that holds a large list of data will give it to you through pagination. Returning ten million items at once will take a very long time. Instead there will be multiple pages, and you must iterate through each page to get it all.
If you need to render something, you can start by rendering based on the initial data.
This usually involves passing a query string for each successive page. Sometimes, you can also use a query string to modify the number of results on each page. What this looks like will depend on the API format, as there are multiple ways to indicate pagination.
Page numbers are the simplest ways. Often, the returned JSON will not even mention what page you are on. Your returned results will be dependent on what page you request. Usually follows a scheme like www.api.website.com/items?page=3.
Cumulatively counting items, also called offset pagination is similar to page numbers, but you request the next page depending on how many items you have already seen. This requires you to keep track of the count. These often follow a scheme like www.api.website.com/items?offset=500.
On a similar vein, you can request after a timestamp offset. This might look like www.api.website.com/items?created:gte:2020-11-23T00:00:00. These can be difficult, as timezones are always annoying.
Sometimes you request the next page depending on the ID of last item in the current page JSON. This is more comprehensive, as you do not need to know the current page number to request the next. These often follow a scheme like www.api.website.com/items?after=zbx43ks, where zbx43ks is the ID of the last item on the previous page.
Since bash handles loops, you can paginate with curl, but you will usually want these items in a program. As such, let’s look at two examples.
Example with Page Numbers - Github Jobs & Ruby
The GitHub jobs API is wonderfully simple, and I highly recommend it to those just starting out with JSON APIs. It is quite simple: for any page, there is a corresponding json page. Just add .json to the end of the url.
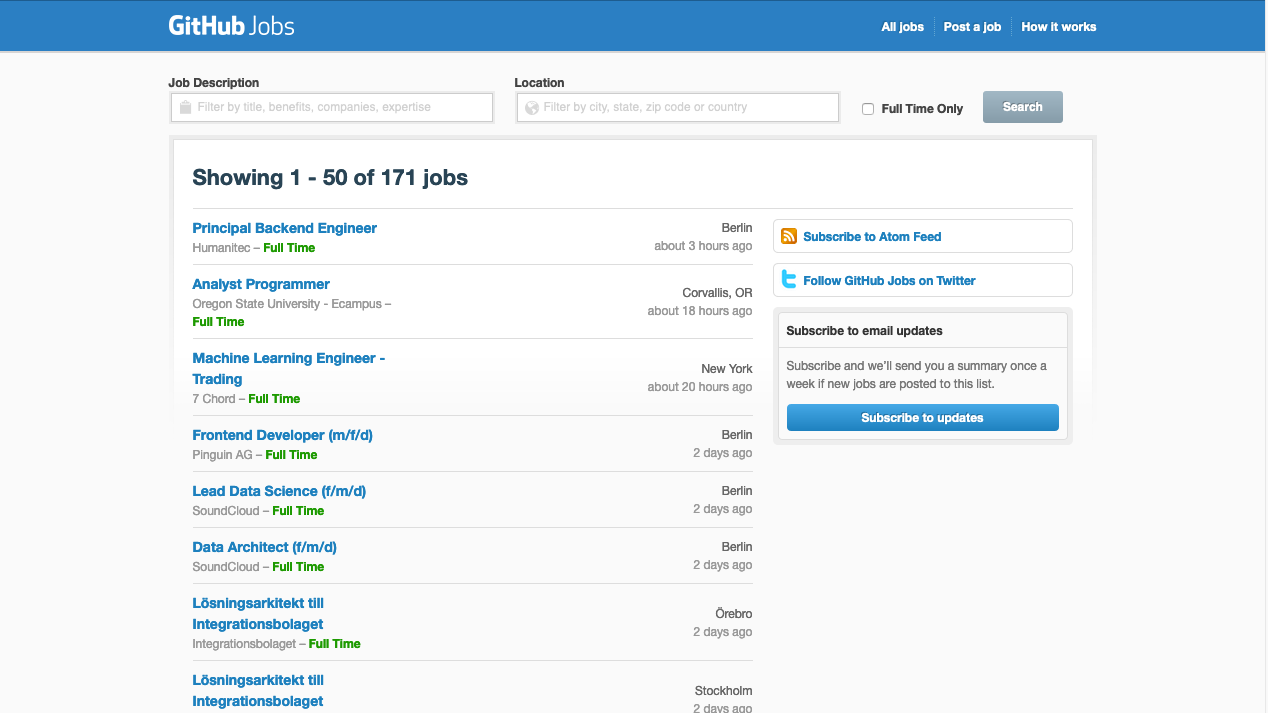  |
| The “Positions” page, along with its corresponding json |
The API takes a query string page. Each page will start where the previous one ended. Pretty simple. Note I think the pages start at 1, contrary to what the API says.
There is no way of knowing how many pages there are, but that is no problem. Since the JSON returned is just an array, we can check to see if the array is empty. Here is an example in Ruby to scrape all of the positions:
require 'net/http'
require 'json'
url = "https://jobs.github.com/positions.json"
page = 1
positions = []
loop do
page_url = url + "?page=" + page.to_s
puts "on page" + page.to_s
uri = URI.parse(URI.escape(page_url))
response = Net::HTTP.get_response(uri)
data = JSON.parse(response.body)
if data.empty?
break
end
positions += data
page += 1
end
Example with ID of Last Item - Reddit & Python
According to the Reddit API:
Listings do not use page numbers because their content changes so frequently.
Instead, pagination is dependent on the IDs of the elements of the current page.
You can access the JSON version of a Reddit page like above - appending .json to the site url. For example, typing reddit.com/r/popular.json returns json that looks like this:
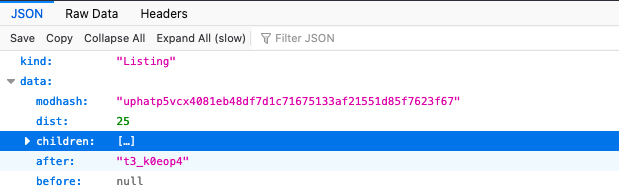
First there is the page’s kind: Listing, which just means a list of posts. If we want to grab all of the posts, we should look at data.
The contents of children is an array of posts. Each post has a lot of information, so I collapsed it for brevity. There are 25 elements in the children array, so we can assume that dist is the number of children.
Finally, there is the after field. In case you are unfamiliar with Reddit IDs, this field is the ID of a post. In this case, it has the ID of the last post in the array. You can double check this yourself, by going to the endpoint and comparing the after field with the final array element’s data.name.
In my opinion, the Reddit API documentation is not great, but we can infer what this means for ourselves. If I try hitting the same endpoint, but inserting the query string (reddit.com/r/popular.json?after=t3_k0eop4), I get a new array of posts. If I go to reddit.com/r/popular without the json, I can go between the first and second page and compare the posts to the two json endpoints we just looked at. In this case, the one without query strings matches page 1, and the posts of page 2 match the json with the query string.
We can infer that the after field can be passed as a URL query string to facilitate pagination. Here is a simple Python script to get the first 10 pages worth of posts:
import requests
url = "https://www.reddit.com/r/popular.json"
posts = []
after = ''
for page in range(0, 10):
page_url = url
if after:
page_url += '?after=' + after
# Reddit shuts down Python requests unless they have a custom user agent
# See: https://www.reddit.com/r/redditdev/comments/3qbll8/
listing = requests.get(page_url, headers={'User-Agent': 'Pagination Example'}).json()
posts += listing['data']['children']
after = listing['data']['after']